Publications
Feel free to browse our previous publications to learn more about our advancing computer vision technology!

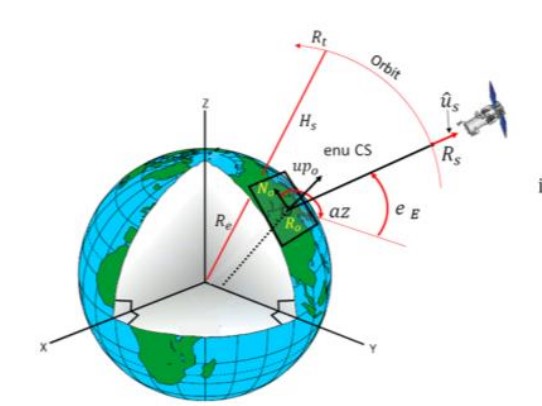
This paper describes a system for generating digital 3D models of spacecraft from 2D imagery collected on-orbit. The 3D model represents the surface location as well as regions of uncertain geometry due to insufficient information and thus can be used to inform optimal future collection paths. The reconstruction method is demonstrated on real on-orbit imagery of the Intelsat 10-02 commercial communications satellite collected by Northrup Grumman’s MEV-2 space vehicle and released publicly via YouTube. Despite low image quality and the lack of available sensor metadata, we demonstrate the feasibility of recovering a 3D representation of the target spacecraft.
3D Spacecraft Reconstruction from On-Orbit Imagery
AuthorsDaniel Crispell, Scott Richardson
- Authors
- Daniel Crispell, Scott Richardson
- Date
- 11 October 2022
- Source
- 3rd Space Imaging Workshop
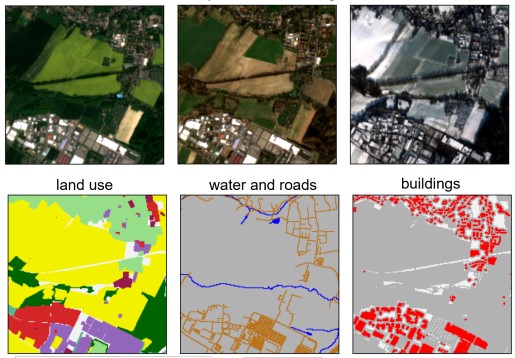
Remote sensing data is plentiful, but downloading, organizing, and transforming large amounts of data into a format readily usable by modern machine learning methods is a challenging and labor-intensive task. We present the OpenSentinelMap dataset, which consists of 137,045 unique 3.7 km2 spatial cells, each containing multiple multispectral Sentinel-2 images captured over a 4 year time period and a set of corresponding per-pixel semantic labels derived from OpenStreetMap data. The labels are not necessarily mutually exclusive, and contain information about roads, buildings, water, and 12 land-use categories. The spatial cells are selected randomly on a global scale over areas of human activity, without regard to OpenStreetMap data availability or quality, making the dataset ideal for both supervised, semi-supervised, and unsupervised experimentation. To demonstrate the effectiveness of the dataset, we a) train an off-the-shelf convolutional neural network with minimal modification to predict land-use and building and road location from multispectral Sentinel-2 imagery and b) show that the learned embeddings are useful for downstream fine-grained classification tasks without any fine-tuning.
OpenSentinelMap: A Large-Scale Land Use Dataset using OpenStreetMap and Sentinel-2 Imagery
AuthorsNoah Johnson, Wayne Treible, Daniel Crispell
- Authors
- Noah Johnson, Wayne Treible, Daniel Crispell
- Date
- 25 April 2022
- Source
- EarthVision 2022 (CVPR Workshop)
This article describes an investigation of the source of geospatial error in digital surface models (DSMs) constructed from multiple satellite images. In this study, the uncertainty in surface geometry is separated into two spatial components: global error that affects the absolute position of the surface and local error that varies from surface point to surface point. The global error component is caused by inaccuracy in the satellite imaging process, mainly due to uncertainty in the satellite position and orientation (pose) during image collection. The key sources of local error are lack of surface appearance texture, shadows, and occlusion. These conditions prevent successful matches between the corresponding points in the images of a stereo pair. A key result of the investigation is a new algorithm for determining the absolute geoposition of the DSM that reflects the pose covariance of each satellite during image collection. This covariance information is used to weigh the evidence from each image in the computation of the global position of the DSM. The use of covariance information significantly decreases the overall uncertainty in global position and results in a 3-D covariance matrix for the global accuracy of the DSM. This covariance matrix defines a confidence ellipsoid within which the actual error must reside. Moreover, the absolute geoposition of each image is refined to the reduced uncertainty derived from the weighted evidence from the entire image set. This article also describes an approach to the prediction of local error in the DSM surface. The observed variance in surface position within a single stereo surface reconstruction defines the local horizontal error. The variance in the fused set of elevations from multiple stereo pairs at a single DSM location defines the local vertical error. These accuracy predictions are compared to ground truth provided by light detection and ranging (LiDAR) scans of the same geographic region of interest. The prediction of global and local error is compared to the actual errors for several geographic locations and mixes of satellite type. The predicted error bounds contain the observed errors according to the allowed percentage of outliers.
Error Propagation in Satellite Multi-Image Geometry
AuthorsJoseph L. Mundy, Hank J. Theiss
- Authors
- Joseph L. Mundy, Hank J. Theiss
- Date
- 16 November 2021
- Source
- IEEE Transactions on Geoscience and Remote Sensing

Designing robust activity detectors for fixed camera surveillance video requires knowledge of the 3-D scene. This paper presents an automatic camera calibration process that provides a mechanism to reason about the spatial proximity between objects at different times. It combines a CNN-based camera pose estimator with a vertical scale provided by pedestrian observations to establish the 4-D scene geometry. Unlike some previous methods, the people do not need to be tracked nor do the head and feet need to be explicitly detected. It is robust to individual height variations and camera parameter estimation errors.
4-D Scene Alignment in Surveillance Video
AuthorsRobert Wagner, Patrick Feeney, Daniel Crispell, Joseph Mundy
- Authors
- Robert Wagner, Patrick Feeney, Daniel Crispell, Joseph Mundy
- Date
- 15 October 2019
- Source
- 2019 IEEE Applied Imagery Pattern Recognition Workshop (AIPR)

Digital Surface Model generation from satellite imagery is a difficult task that has been largely overlooked by the deep learning community. Stereo reconstruction techniques developed for terrestrial systems including self driving cars do not translate well to satellite imagery where image pairs vary considerably. In this work we present neural network tailored for Digital Surface Model generation, a ground truthing and training scheme which maximizes available hardware, and we present a comparison to existing methods. The resulting models are smooth, preserve boundaries, and enable further processing. This represents one of the first attempts at leveraging deep learning in this domain.
Learning Dense Stereo Matching for Digital Surface Models from Satellite Imagery
AuthorsWayne Treible, Scott Sorensen, Andrew D. Gilliam, Chandra Kambhamettu, Joseph L. Mundy
- Authors
- Wayne Treible, Scott Sorensen, Andrew D. Gilliam, Chandra Kambhamettu, Joseph L. Mundy
- Date
- 11 December 2018
- Source
- arxiv.org
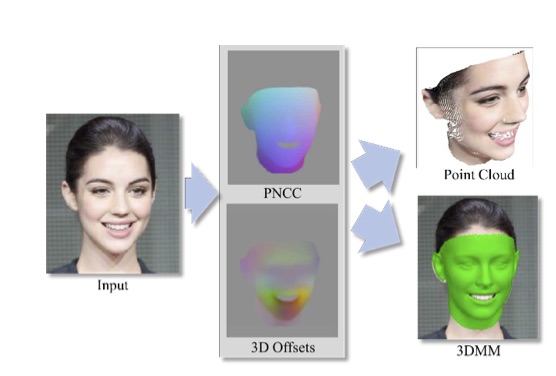
An efficient, fully automatic method for 3D face shape and pose estimation in unconstrained 2D imagery is presented. The proposed method jointly estimates a dense set of 3D landmarks and facial geometry using a single pass of a modified version of the popular “U-Net” neural network architecture. Additionally, we propose a method for directly estimating a set of 3D Morphable Model (3DMM) parameters, using the estimated 3D landmarks and geometry as constraints in a simple linear system. Qualitative modeling results are presented, as well as quantitative evaluation of predicted 3D face landmarks in unconstrained video sequences.
Pix2Face: Direct 3D Face Model Estimation
AuthorsDaniel Crispell and Maxim Bazik
- Authors
- Daniel Crispell and Maxim Bazik
- Date
- 30 March 2018
- Source
- ICCV 2017: 300 3D Facial-Videos In-The-Wild Challenge Workshop
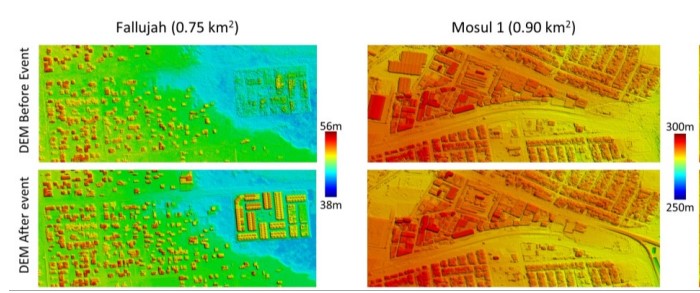
This paper presents the innovative SatTel framework, designed to automatically access, collate, process, and exploit commercial satellite imagery from a wide variety of vendors. Established vendors such as DigitalGlobe provide high resolution imagery with limited coverage, while disruptive vendors such as Planet and BlackSky provide low resolution imagery with near global coverage. SatTel provides a single point of entry for exploitation of these contrasting and complementary vendor capabilities. The authors illustrate the value of the SatTel framework via demonstrative change detection capabilities. SatTel change detection from small satellite imagery based on comparison of image to image appearance achieves mean average precision (MAP) above 0.75 for many sites compared to ground truth analyst annotation. SatTel change detection from high resolution satellite imagery based on multidimensional geometric structures achieves an average precision of 0.84 for elevation changes above 3.0 meters compared to ground truth analyst annotation.
SatTel: A Framework for Commercial Satellite Imagery Exploitation
AuthorsAndrew D. Gilliam, Thomas B. Pollard, Andrew Neff, Yi Dong, Scott Sorensen, Robert Wagner, Selene Chew, Todd V. Rovito, Joseph L. Mundy
- Authors
- Andrew D. Gilliam, Thomas B. Pollard, Andrew Neff, Yi Dong, Scott Sorensen, Robert Wagner, Selene Chew, Todd V. Rovito, Joseph L. Mundy
- Date
- 12 March 2018
- Source
- 2018 IEEE Winter Conference on Applications of Computer Vision (WACV)

We present a feature-based visual SLAM system for aerial video whose simple design permits near real-time operation, and whose scalability permits large-area mapping using tens of thousands of frames, all on a single conventional computer. Our approach consists of two parallel threads: the first incrementally creates small locally consistent submaps and estimates camera poses at video rate; the second aligns these submaps with one another to produce a single globally consistent map via factor graph optimization over both poses and landmarks. Scale drift is minimized through the use of 7-degree-of-freedom similarity transformations during submap alignment. We quantify our system’s performance on both simulated and real data sets, and demonstrate city-scale map reconstruction accurate to within 2 meters using nearly 90,000 aerial video frames - to our knowledge, the largest and fastest such reconstruction to date.
Global-Local Airborne Mapping (GLAM): Reconstructing a City from Aerial Videos
AuthorsHasnain Vohra, Maxim Bazik, Matthew Antone, Joseph Mundy, William Stephenson
- Authors
- Hasnain Vohra, Maxim Bazik, Matthew Antone, Joseph Mundy, William Stephenson
- Date
- 30 May 2017
- Source
- Tech Report
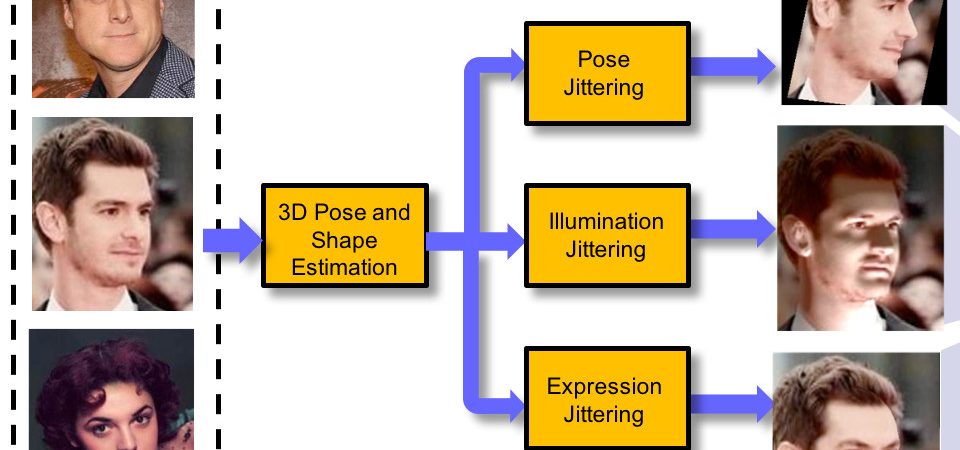
The performance of modern face recognition systems is a function of the dataset on which they are trained. Most datasets are largely biased toward “near-frontal” views with benign lighting conditions, negatively effecting recognition performance on images that do not meet these criteria. The proposed approach demonstrates how a baseline training set can be augmented to increase pose and lighting variability using semi-synthetic images with simulated pose and lighting conditions. The semi-synthetic images are generated using a fast and robust 3D shape estimation and rendering pipeline which includes the full head and background. Various methods of incorporating the semi-synthetic renderings into the training procedure of a state of the art deep neural network-based recognition system without modifying the structure of the network itself are investigated. Quantitative results are presented on the challenging IJB-A identification dataset using a state of the art recognition pipeline as a baseline.
Dataset Augmentation for Pose and Lighting Invariant Face Recognition
AuthorsDaniel Crispell, Octavian Biris, Nate Crosswhite, Jeffrey Byrne, Joseph L. Mundy
- Authors
- Daniel Crispell, Octavian Biris, Nate Crosswhite, Jeffrey Byrne, Joseph L. Mundy
- Date
- 30 May 2017
- Source
- 2016 IEEE Applied Imagery Pattern Recognition Workshop (AIPR)

This paper addresses the problem of determining the location of a ground level image by using geo-referenced overhead imagery. The input query image is assumed to be given with no meta-data and the content of the image is to be matched to a priori constructed reference representations. The proposed 3D geo-localization framework performs better than the 2D approach for 75 % of the query images.
Geo-localization using Volumetric Representations of Overhead Imagery
AuthorsOzge C. Ozcanli, Yi Dong, Joseph L. Mundy
- Authors
- Ozge C. Ozcanli, Yi Dong, Joseph L. Mundy
- Date
- 04 February 2016
- Source
- International Journal of Computer Vision (IJCV), Volume 116, Issue 3, pp 226-246

In this paper, an automatic geo-location correction framework that corrects multiple satellite images simultaneously is presented. As a result of the proposed correction process, all the images are effectively registered to the same absolute geodetic coordinate frame. The usability and the quality of the correction framework are shown through probabilistic 3D surface model reconstruction. The models given by original satellite geo-positioning meta-data and the corrected meta-data are compared and the quality difference is measured through an entropy-based metric applied onto the high resolution height maps given by the 3D models.
A Comparison of Stereo and Multiview 3D Reconstruction Using Cross-sensor Satellite Imagery
AuthorsOzge C. Ozcanli, Yi Dong, Joseph L. Mundy
- Authors
- Ozge C. Ozcanli, Yi Dong, Joseph L. Mundy
- Date
- 04 February 2016
- Source
- International Journal of Computer Vision (IJCV), Volume 116, Issue 3, pp 226-246
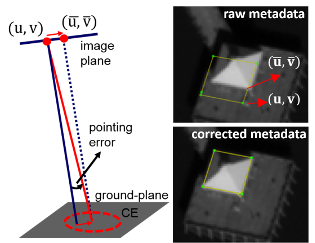
Modern satellites tag their images with geolocation information using GPS and star tracking systems. Depending on the quality of the geopositioning equipment, errors may range from a few meters to tens of meters on the ground. In this paper, an automatic geolocation correction framework that corrects images from multiple satellites simultaneously is presented. As a result of the proposed correction process, all the images are effectively registered to the same absolute geodetic coordinate frame.
Automatic Geo-location Correction of Satellite Imagery
AuthorsOzge C. Ozcanli, Yi Dong, Joseph L. Mundy, Helen Webb, Riad Hammoud, Victor Tom
- Authors
- Ozge C. Ozcanli, Yi Dong, Joseph L. Mundy, Helen Webb, Riad Hammoud, Victor Tom
- Date
- 23 June 2014
- Source
- International Journal of Computer Vision (IJCV), Volume 116, Issue 3, pp 263-277
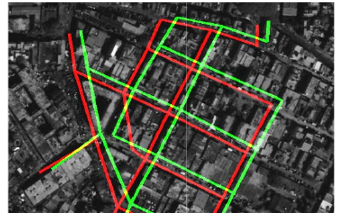
Modern satellites tag their images with geolocation information using GPS and star tracking systems. Depending on the quality of the geopositioning equipment, errors may range from a few meters to tens of meters on the ground. In this paper, an automatic geolocation correction framework that corrects images from multiple satellites simultaneously is presented. As a result of the proposed correction process, all the images are effectively registered to the same absolute geodetic coordinate frame.
Automatic Geo-location Correction of Satellite Imagery
AuthorsOzge C. Ozcanli, Yi Dong, Joseph L. Mundy, Helen Webb, Riad Hammoud, Victor Tom
- Authors
- Ozge C. Ozcanli, Yi Dong, Joseph L. Mundy, Helen Webb, Riad Hammoud, Victor Tom
- Date
- 23 June 2014
- Source
- International Journal of Computer Vision (IJCV), Volume 116, Issue 3, pp 263-277
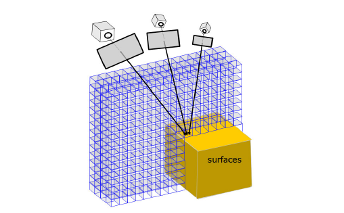
A new technique to optimize volumetric representation and advances in graphics processing have enabled efficient construction of 3D models from 2D imagery, while fully capturing the uncertainty in the data.
3D Modeling Using Miniscule Volume Elements
AuthorsOzge Ozcanli, Daniel Crispell, Joseph Mundy, Vishal Jain, and Tom Pollard
- Authors
- Ozge Ozcanli, Daniel Crispell, Joseph Mundy, Vishal Jain, and Tom Pollard
- Date
- 01 August 2012
- Source
- SPIE Newsroom
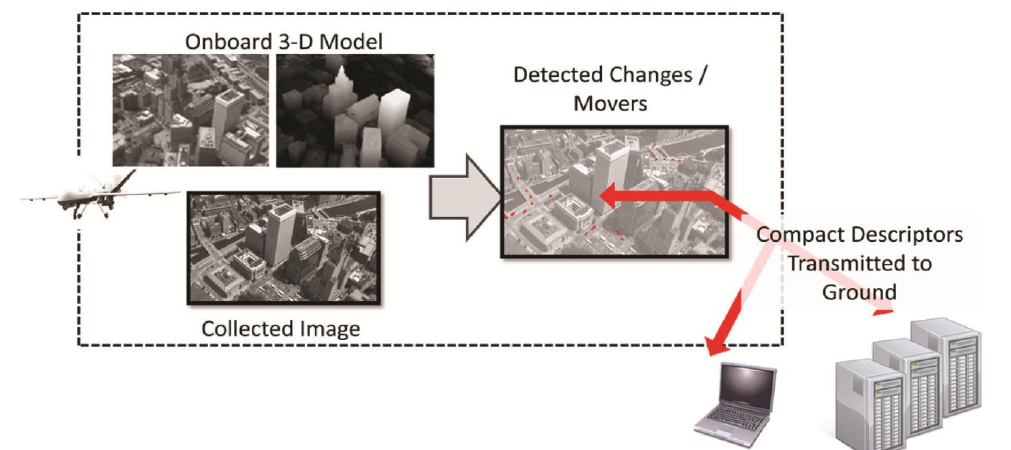
Extracting useful geospatial data from imagery is a fundamental challenge that has seen significant growth over the years as technology advances have been brought to bear on the problem. An important component of this problem addresses how the data should be represented to ensure the information content is accurately captured, preserved, and conveyed to consumers. Much of the information contained in the imagery is redundant and should be transformed so that only the essential information is retained and stored, allowing the redundant data to be discarded. An efficient mechanism for achieving this goal is the 3D Voxel model.
Three-Dimensional Volume Representation for Geospatial Data in Voxel Models
AuthorsF. Tanner, D. Crispell, and R. Isbell
- Authors
- F. Tanner, D. Crispell, and R. Isbell
- Date
- 13 March 2012
- Source
- ASPRS 2012 Annual Conference
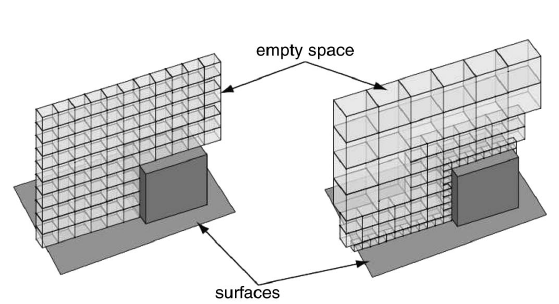
Given a set of high-resolution images of a scene, it is often desirable to predict the scene’s appearance from viewpoints not present in the original data for purposes of change detection. When significant 3D relief is present, a model of the scene geometry is necessary for accurate prediction to determine surface visibility relationships. In the absence of an a priori high-resolution model (such as those provided by LIDAR), scene geometry can be estimated from the imagery itself.
A Variable-Resolution Probabilistic Three-Dimensional Model for Change Detection
AuthorsD. Crispell, J. L. Mundy, and G. Taubin
- Authors
- D. Crispell, J. L. Mundy, and G. Taubin
- Date
- 19 January 2012
- Source
- IEEE Transactions on Geoscience and Remote Sensing

An efficient, fully automatic method for 3D face shape and pose estimation in unconstrained 2D imagery is presented. The proposed method jointly estimates a dense set of 3D landmarks and facial geometry using a single pass of a modified version of the popular “U-Net” neural network architecture. Additionally, we propose a method for directly estimating a set of 3D Morphable Model (3DMM) parameters, using the estimated 3D landmarks and geometry as constraints in a simple linear system. Qualitative modeling results are presented, as well as quantitative evaluation of predicted 3D face landmarks in unconstrained video sequences.
Real-Time Rendering and Dynamic Updating of 3D Volumetric Data
AuthorsAndrew Miller, Vishal Jain, & Joseph Mundy
- Authors
- Andrew Miller, Vishal Jain, & Joseph Mundy
- Date
- 05 March 2011
- Source
- Fourth Workshop on General Purpose Processing on Graphics Processing Units